In the case of the DL_MG multigrid solver, we have applied the capability of the MPI-3 standard to use shared memory for MPI ranks on the same node in order to reduce MPI data traffic while preserving the more structured communication environment offered by MPI. Results from this work were presented at the 13th Copper Conference on Iterative Methods.
- Comparing Parallel Performance for a Geometric Multigrid Solver Using Hybrid Parallelism, MPI Shared Memory and Multiple GPUs , L. Anton, V, Szeremi and M. Mawson, 13th Copper Mountain Conference on Iterative Methods, Copper Mountain, Colorado, USA, 7-11 April 2014
Shared memory is also very useful for distributed FFTs as it can help significantly to reduce data traffic within the shared memory node.
The figure (below) shows that our shared memory FFT extends the scaling range by about five times for the FFT computation in the gyrokinetic plasma code GS2
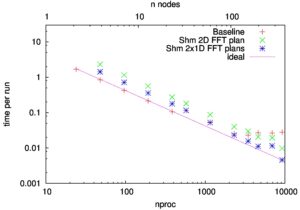
The performance data were collected on the ARCHER system.
A presentation about this work is available:
- Exploiting Shared Memory to Extend the Scalability of GS2: Status and Plans, L. Anton, GS2 Development Meeting, CCFE, Culham, 26th-27th November 2014
Web Resources
We note that earlier work by Ian Bush (now at the Oxford e-Research Centre) used shared memory segments and semaphores from Posix-compliant System V Inter-Process Communication (IPC) features. This work was published in New Fortran Features: The Portable Use of Shared Memory Segments, I.J.Bush, HPCx Technical Report HPCxTR0701